Don't Let the Agent Grade Its Own Homework
I spent last week adding smarter OAuth to how Tern signs into Github. Should be straightforward, except I’m kind of an idiot at OAuth, and I kept discovering quirks of GitHub’s model as I went. We install a Github App, but if you try to re-install, the user flow dead-ends. Personal OAuth is different than App installs. Callback parameters that only show up sometimes. Edge cases where the user already has the app installed but on a different org. Fascinating stuff, I know.
I was building with Claude. Every time I learned something, I updated my mental model, Claude updated the code, and we’d find the next thing. Whack-a-mole. After a few rounds of this I realized that while it sounded like Claude got it, the code wasn’t keeping up. Too many entry points, too many states the system could be in. I kept burning context and focus asking “wait, did you get the setting page, too?”
So I made a spreadsheet. 28 code locations. 4 columns: Fresh Connect, Disconnect, Reconnect Same Org, Reconnect Different Org. And a Verdict column. Claude filled it in, and I scanned the results. 3 of 28 flagged as bugs. I looked at each one. Fixed two. The third was a real edge case that I understood and decided to ship with.
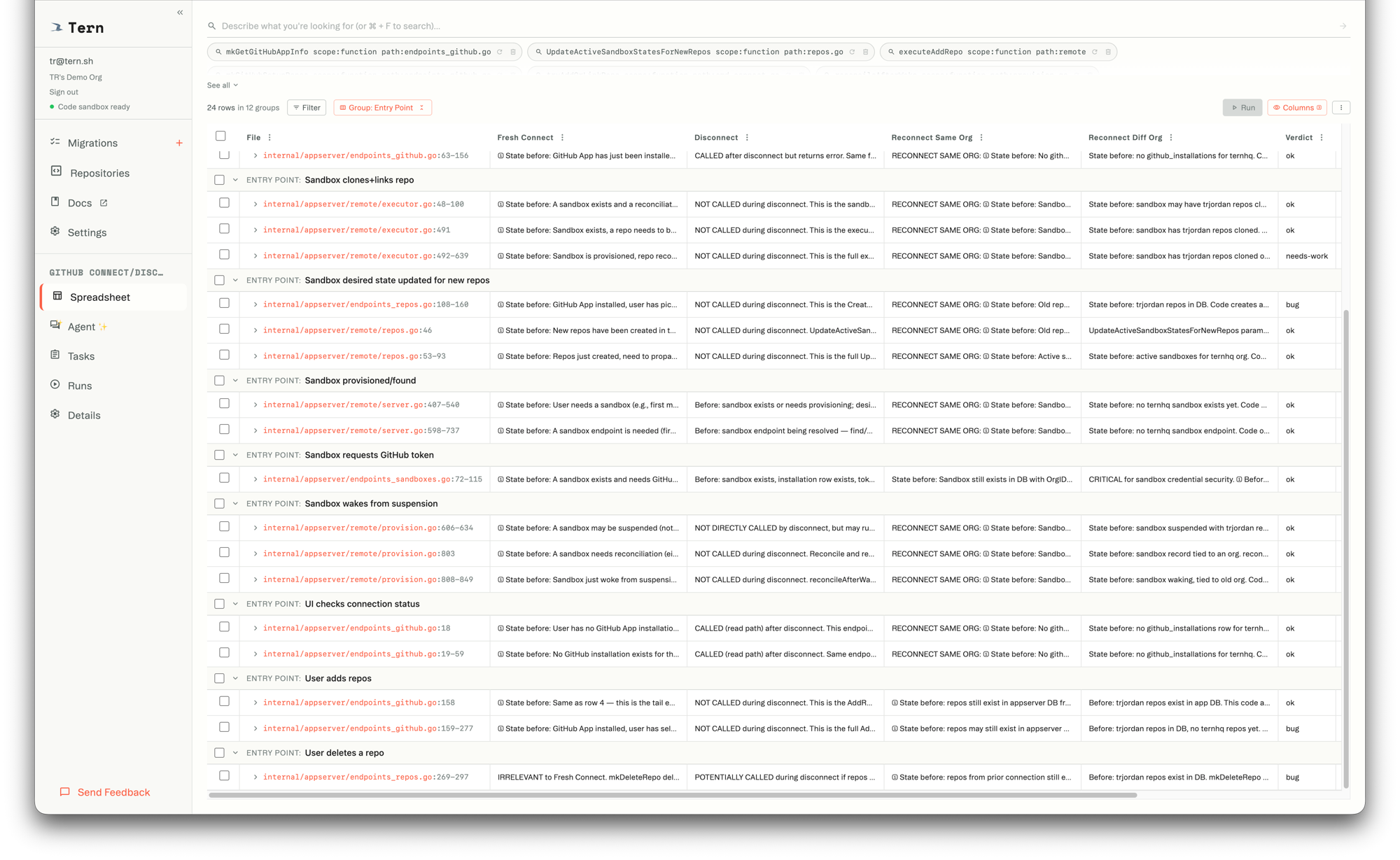
That spreadsheet was the moment I trusted the code. Not the tests, because those passed the whole time. Definitely not Claude’s assurance that it looked good. The spreadsheet forced every entry point and every state into a grid where I could see what Claude thought was happening, at each one, and decide whether I agreed.
Claude would never have done that on its own. It didn’t! It ran the tests, saw them pass, and moved on. That’s what agents do. They use whatever checks are wired up, and when those pass, they’re done.
All coding is faster now. The question is always how much you trust it.
Sometimes the answer is easy. Tests pass, types check, ship it. But the validation a change needs is a function of how risky the change is, not what checks happen to exist. A one-line type fix needs a green CI run. A refactor that touches auth middleware across 60 endpoints needs someone reading the diff, checking staging, watching the deploy.
Humans calibrate this naturally. You look at a change and decide how much scrutiny it deserves. You climb a ladder:
- Read all the relevant code. Make sure it’s in-context.
- Delegate the reading. Summarize large swaths that would swamp the context window.
- Run linters, typecheckers, tests.
- Write custom scripts that check the work.
- Write custom scripts that use AI to check the work. Playwright, visual diffing.
- Run off-machine checks. Visual regression, load tests, staging deploys.
- Ship to prod. Watch the metrics.
Agents don’t calibrate. They use whatever checks are wired up, and when those pass, they’re done. Not because the agent is lazy. Because it has no way to know that this particular change needed more.
The validation a change needs and the validation an agent can do are completely different questions. Nothing bridges them. The agent does the work, runs what it has, and moves on.
It’s grading its own homework.
You already know the fix. You’ve known it your entire career: the code doesn’t get to decide whether it passes. The test does. The check is external.
That principle applies to every rung. The agent does the work, and something else decides whether it’s finished — calibrated to what the change actually requires.
Nobody’s built that.
The entire AI coding ecosystem runs on feedback infrastructure that predates LLMs. Linters, typecheckers, test suites. All wired up, all programmatic, all built for humans. The rest of the ladder — custom checks, staging verification, production monitoring — humans do that by hand. There’s no programmatic version. Agents skip it.
The shape of what’s missing: I have X things, and I want to ask Y questions of each of them. Rows are code locations tied to real commits. Columns are checks — run by agents, static analysis, tests, whatever the change demands. The agent iterates against external criteria it can’t fudge. It does the work, calls “re-check me,” and the system says whether it’s done.
That’s what has to exist before AI coding gets past fast and into trusted.
This is what we’re building at Tern. A spreadsheet where the rows are your code and the columns are your questions. The agent does the work. The spreadsheet keeps score.